Improving GRPO data efficiency with budget forcing
Reinforcement learning (RL) fine-tuning has proved to be highly effective at inducing strong reasoning capabilities of large language models (see DeepSeek-R1). However, these methods are notoriously data hungry, requiring large amounts of high quality data. Collecting that much high quality reasoning data is expensive and time-consuming.
So, I asked: Can we get the same improvements with less data?
My idea was to apply a simple but potentially powerful trick to the RL fine-tuning process: budget forcing.
What is Budget Forcing?

Normally, when an LLM is solving a math or reasoning problem, thinking may end prematurely, resulting in an incorrect answer. Introduced in s1: Simple test-time scaling, budget forcing is the process of forcfully extending the models thinking process to reach a minimum token budget (i.e., “thinking time”).
Concretly, if the model tries to stop its reasoning trace by outputting a </think> token (i.e., the end of thinking token) and the response length falls below the given minimum token budget n, we extend thinking by replacing </think> with the Wait token. The authors show that applying budget forcing at test-time can significantly improve the performance of reasoning models.
My idea was to apply budget forcing within the RL sampling process itself. More correct answers = more reward signal = better data efficiency. To provide some motivation for this, I computed the accuracy of the Qwen-2.5-3B-Instruct model on 32 MATH (level 3-5) problems, evaluated over 16 responses per problem. During evaluation, I used budget forcing and considered a range of minimum budgets.
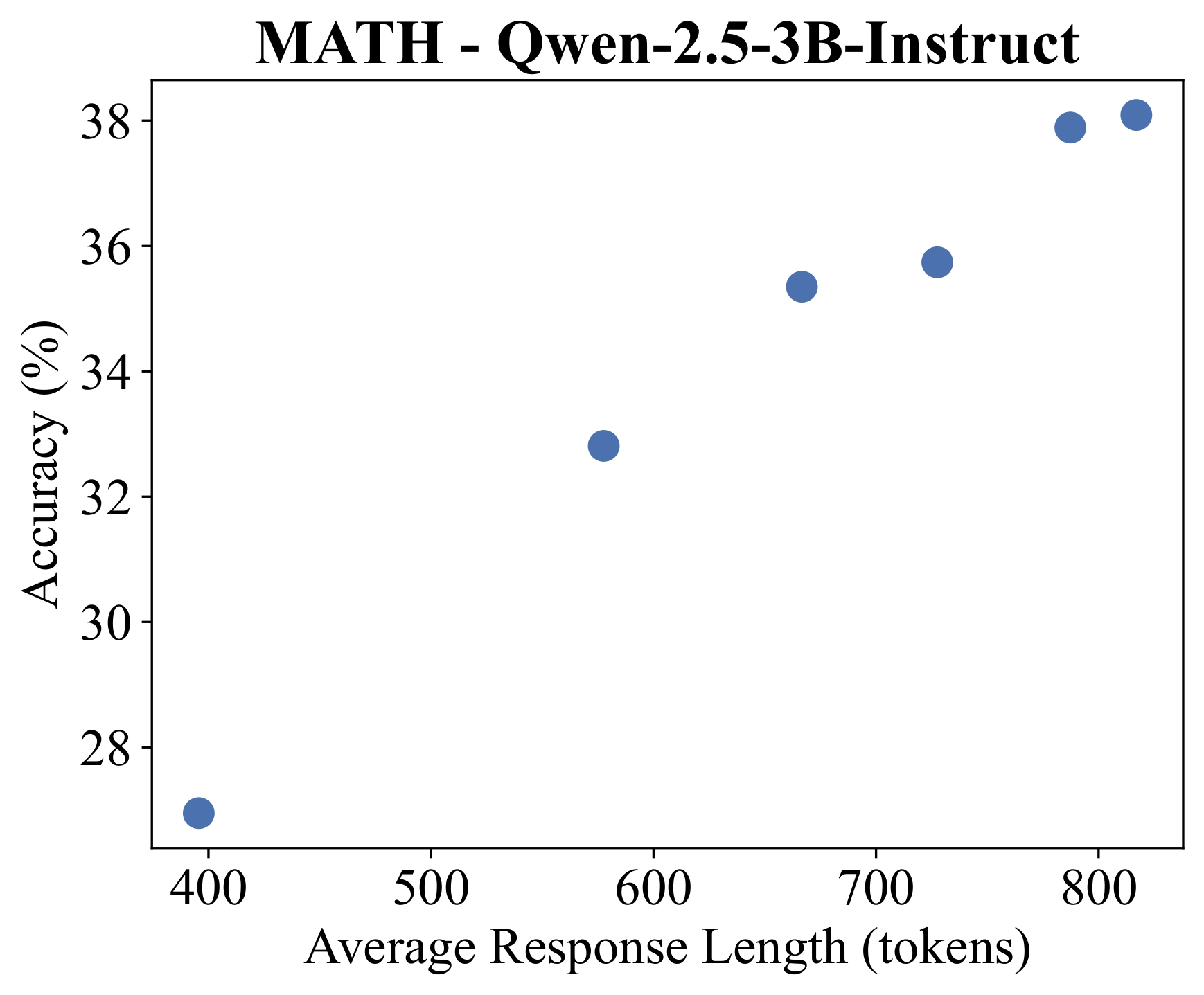
As can be seen in the figure above, as the minimum budget increases, both average response length and accuracy increase significantly.
Group Relative Policy Optimization (GRPO)
The RL fine-tuning algorithm I considered is Group Relative Policy Optimization (GRPO)–the method behind the success of DeepSeek-R1. Unlike Proximal Policy Optimization (PPO), GRPO does not require a critic model which can often be as large as the base model itself.
Instead, GRPO works by sampling a group of model responses to each reasoning problem. For each response, a rule-based correctness reward (1 if the answer is correct, 0 otherwise) is computed simply by parsing the response text. GRPO then normalizes these rewards within the group to estimate an advantage signal - essentially, how much better or worse a response is compared to the others in the same group. At every training step, we sample responses from the model, compute group relative advantages, and then update the model parameters using the GRPO objective function.
In short, GRPO is well-suited for tasks where correctness can be checked automatically, like reasoning problems where there is only one correct answer.
Method: Budget Forced Sampling during RL Fine-tuning
I integrate budget forcing into the RL fine-tuning process by applying it during the sampling step of GRPO training:
- If the model ended its reasoning trace too early (before the minimum token budget was reached), I appended the
Waittoken to force it to continue generating.1 - This ensured that the model spent more time “thinking” before providing its answer. I hypothesized that by applying budget forcing during the GRPO sampling process, the percentage of correct responses within a group will increase, thus improving sample efficiency and accelerating learning.
Everything else in the GRPO training pipeline–rewards, advantage estimation, GRPO objective–was kept exactly the same as in the baseline. In particular, no budget forcing is applied at test-time.
Experiments
To evaluate the effect of budget forcing in RL fine-tuning, I designed a series of experiments varying the model size, task difficulty, and minimum token budgets. The goal was to see whether budget forcing improves sample efficiency in RL fine-tuning.
Setup
Models: I considered the Qwen-2.5-3B-Instruct and Qwen-2.5-7B-Instruct models. To fit training with the compute limitations, I used LoRA (rank 64) adapters for parameter-efficient fine-tuning.
Datasets:
- GSM8K – grade-school math word problems (easier reasoning task).
- MATH (levels 3-5) – competition-style math problems (harder reasoning task).
Minimum Token Budgets:
- For GSM8K, I tested minimum budgets of 0 (baseline), 256, and 512 tokens.
- For MATH, I tested 0 (baseline), 640, 768, 896, and 1024 tokens.
All budgets were chosen to be higher than the average response length of the baseline runs.
Compute: I was constrained to 4xA40 GPUs and 2xA100 GPUs.
Results
So, did the budget forced sampling actually help? The short answer is no.
In this blog post, I only show results for Qwen-2.5-3B-Instruct on GSM8K. These are representative of the full set of experiments. For the full set of results, please refer to the complete report here.
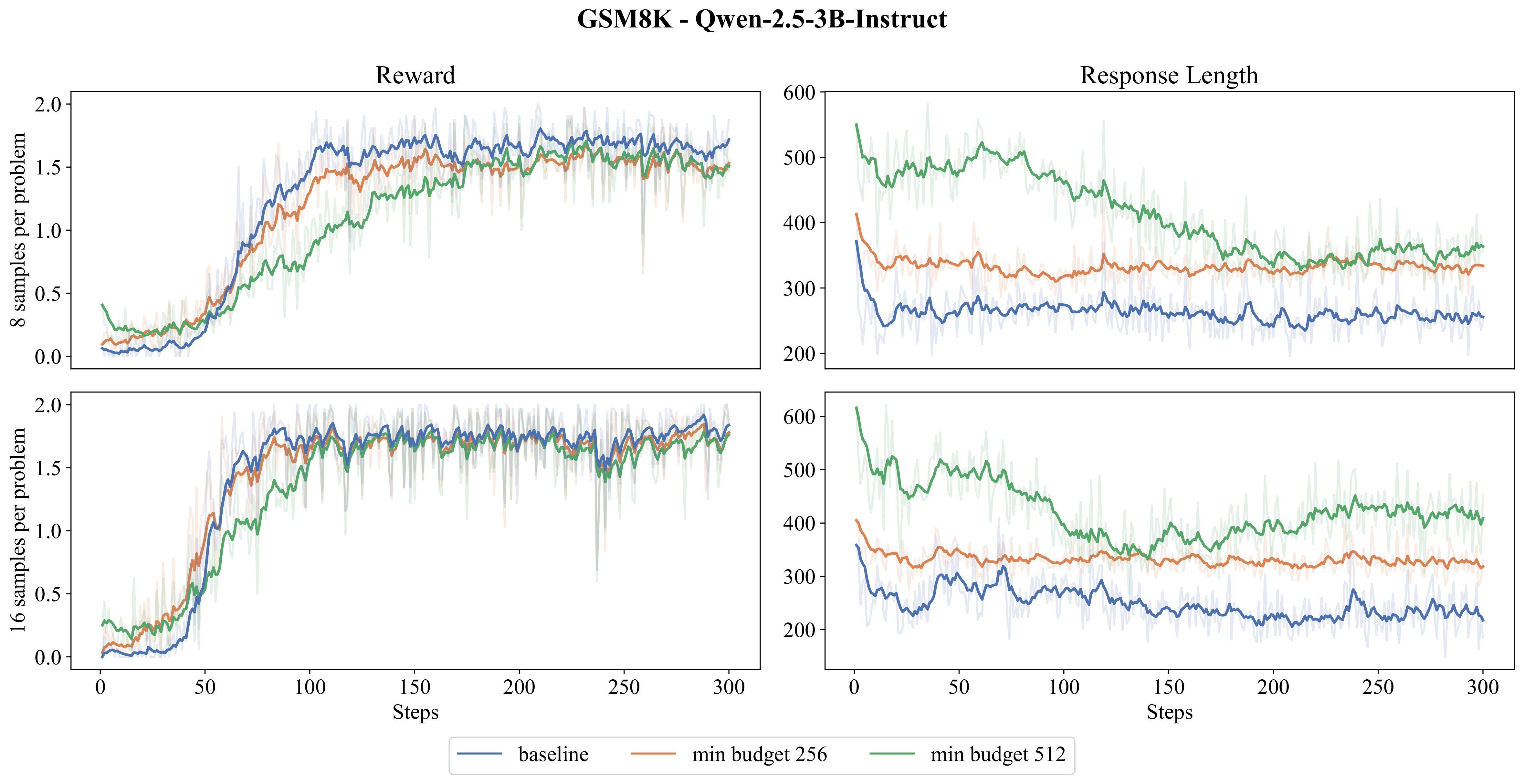
The reward signal and average response length curves during training:
The final test accuracies of Qwen-2.5-3B-Instruct on the GSM8K task:
| min budget | responses-per-problem | Accuracy |
|---|---|---|
| 0 (baseline) | 8 | 77.6% |
| 256 | 8 | 67.9% |
| 512 | 8 | 67.9% |
| 0 (baseline) | 16 | 82.0% |
| 256 | 16 | 79.0% |
| 512 | 16 | 72.6% |
Does budget forcing improve GRPO training?: As can be seen in the reward curves, budget forcing leads to higher reward signal in the early stages of GRPO training. However, these benefits quickly diminish as training progresses and the model underperforms in the long run compared to the baseline. Additionally, models with larger token budgets show higher initial reward but also experience a greater decline in performance.
Do models trained with budget forcing generalize to test-time?: As seen in the table above, models trained with budget forcing consistently show lower test accuracy compared to the baseline.
Limitations
There are a few important caveats to keep in mind about these results:
- Compute constraints: RL fine-tuning is compute-hungry. With only a handful of A40s and A100s available, I had to limit training to relatively small models, short runs, and parameter-efficient LoRA adapters. Larger-scale experiments might paint a different picture.
- Implementation detail: My approach appended
Waitafter</think>instead of replacing it. This kept things efficient in vLLM but may have created “unnatural” responses that the model could exploit. In practive, I found that the budget-forced outputs were often low quality–frequently repeating tokens, sentences, or answers whenever the response was forced to reach the budget. - Train vs. test mismatch: Budget forcing was applied during training but not at test-time, which likely contributed to the performance gap.
Conclusion
Overall, this project was a fun way for me to learn more about AI reasoning, RL fine-tuning methods like GRPO, and test time scaling. While my idea didn’t pan out as hoped, it highlighted the challenges of improving data efficiency in GRPO and game me useful insights.
If you are curious to dive deeper into the project, check out the full report and code:
Acknowledgements: This project was done in collaboration with Yuchong Zhang for a course.
-
In the original paper, budget forcing is applied per response by replacing the
</think>token withWait. For efficiency during GRPO training, I implemented a batch-level version in vLLM. Replacing tokens would have required patching the vLLM backend, so instead I used a LogitsProcessor to simply appendWaitafter</think>, which was much easier to implement while still achieving a similar effect. ↩